Written by Michael Blatt.
CPE: The Grand Unified Theory of Performance
To us, Performance is everywhere.
We live and breathe it, and if there is no code running that we can measure and tweak, some of us turn to something else to measure and tweak instead!
Consider the time and effort spent by audiophiles on optimising their setup. Here, a consultancy of a different kind provides a great intro to the myriad factors that contribute to audio performance. Hint: Minimise the phase distortion!
How important is coaching to athletic performance? No need to be an Olympian to see the benefits of measuring performance and taking action to optimise it, as countless virtual coaches and 55 million casual runners tracking their metrics on Strava.com will tell you. A magazine can elaborate on Why You Need a Running Coach, but deep down the answer is simple: to help you measure and improve performance. To start with, gather metrics and define a baseline.
Even the World Economic Forum (of yearly Davos Singapore meeting fame) has joined in, with a 2017 paper describing a view of DNA as code thanks to the CRISPR gene-editing method.
Performance wants to be measured, tracked, managed and tuned in the spirit of continuous improvement…
But in the world out there, software performance engineering doesn’t apply continuous improvement principles often enough!
Ask most performance testers: their work ends when the code goes live, or, perish the thought, as soon as their latest results report is out!
This state of affairs cannot be allowed to continue.
How do we ensure that performance is taken into account from the start, implemented, verified, managed and that we base our future actions on sound engineering principles?
Enter Continuous Performance Engineering
At Altersis Performance, we call this the principle of Continuous Performance Engineering (CPE) – performance is part of every phase of the application lifecycle, not just testing.
The simplest way is to see CPE as a journey through the lifecycle of an application.
This could be waterfall (across versions), Agile (across sprints), or any other iterative model.
The aim of this journey is to optimise the performance of the application, but also the testing and management of that performance, in a cycle of continuous improvement.
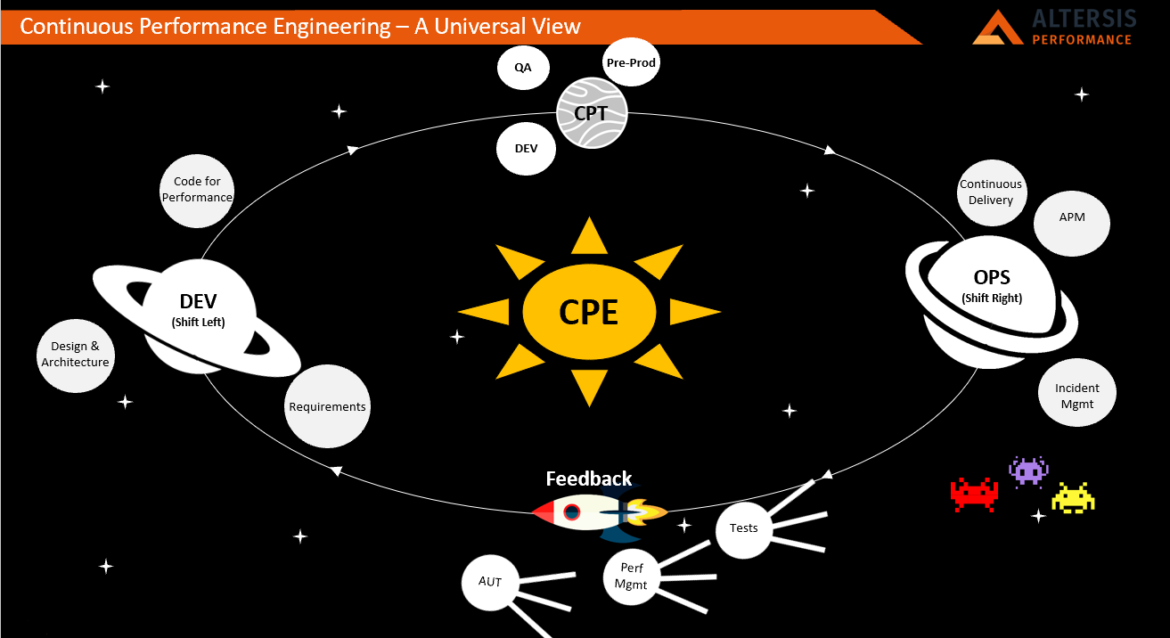
I like to visualise this as a rotating journey around a solar system, as the picture below shows:
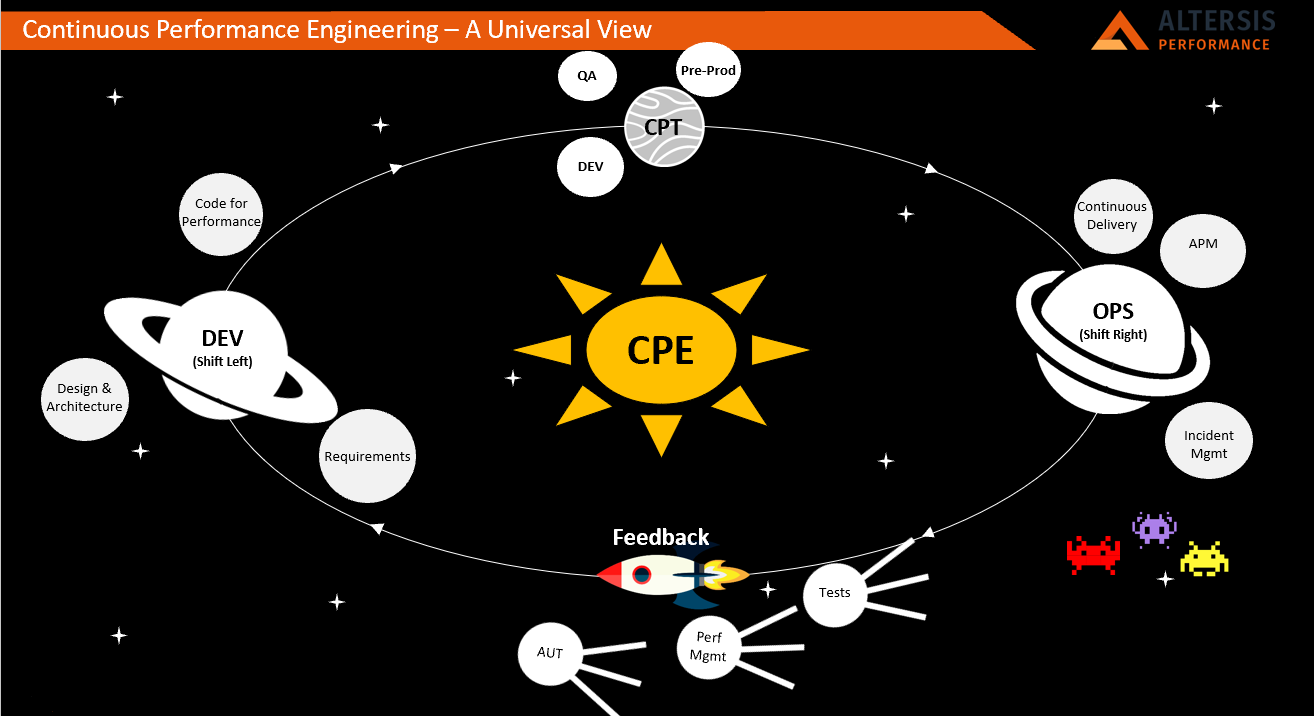
Shift Left
We start by implementing performance in the development stages. This is Dev in the wider sense: engineering valid and correct performance requirements, producing an architecture designed to meet them and the code to deliver the performance required.
Once code compiles, it needs to be verified and tuned as appropriate.
Performance Testing, Continuously
Testing is next, closely associated and often confused with Quality Assurance.
There, we use unit and component tests in development environments, and higher-level tests in the QA/test environments, as well as end-to-end tests including surrounding systems (real or simulated) and APM in the pre-production environment.
Now the application code is ready for deployment to Production, where it needs to be managed.
Shift Right
The application of Performance Engineering principles to the Ops space includes Continuous Delivery (CD) of code to production once validated and the operation of an effective APM solution. It also brings Incident Management into the picture.
As the APM and Incident Management solutions collect information in Ops, no doubt the business already has ideas about what to do next. Time for their technology partners to add to that!
Feedback
Masaaki Imai understood the importance of feedback when he wrote “Kaizen: The Key to Japan’s Competitive Success“, which outlines the Kaizen approach to continuous improvement. Feedback is the first principle.
Without feedback, there is no continuity.
Without continuity, all we have is a glorified code factory, churning out products that may or may not generate business. Engineers are by nature concerned with the efficiency of their product, and it is of course very important; but not as important as the effectiveness of their product; see Effectiveness vs Efficiency for clear examples of the contrast between the two.
So we need to know how effective our engineering has all been, before we optimise that too.
What information can Ops teach us about the product we are developing? Ops need to help us answer the following questions:
- How effective are our tests? Do they predict production performance and utilisation accurately? Do we need to improve our tests to match our objectives more closely?
- How effective is our APM solution? Does it report the performance and business data we need? Does it capture issues when it should, how it should? Does it log the right errors, correctly? Does it confirm production vs anticipated volumes? Do we need to improve the APM solution or update our volumetric models?
- How effective is the application? Does it meet its system performance SLAs? Does the end-user experience meet the requirements? Does it have the amount of headroom planned at this stage of its lifetime? Do we need to improve the requirements or update our assumptions about the application environment (architecture, end users, etc)?
Only with these answers can you contribute meaningfully to the next the next version/build, ensuring a successful implementation of the great new features in the next release!
Conclusion
How does your project, or your organisation measure the application performance? Continuously, or only at certain points?
Could you have more benefit from Shift Left, and also Shift Right performance activities?
What could you do to encourage continuous performance improvement?
Look out for our other blog posts and webinars on this topic – or contact us to talk directly!



0 Comments