‘By Alan Gordon’
In this article I will introduce the concept of Continuous Performance Engineering (CPE), which is our term at ALTERSIS Performance for all performance engineering-related activities that are integrated into the CI/CD (Continuous Integration/Continuous Delivery – or Continuous Deployment) process.
Read on to learn why CPE is important – not just for performance engineers but for developers, DevOps teams and anyone involved in building and supporting applications; what is our approach; and how you can start to benefit from it.
Summary of the key points – for those who are pushed for time
- Finding software performance defects earlier in the software lifecycle is just as important as catching functional defects early, and will save you lots of time and effort.
- With CPE we aim to “Shift Left, Shift Right and Automate Everything” related to software performance engineering
- It is now increasingly easy to “Shift Left” performance tests, that is to say, run them automatically in your CI/CD process, and some people already do this – which is great! Our CPE framework adds to this by integrating other types of performance checks, not only performance tests, into the CI/CD process, to detect as many types of performance defects as possible.
- Additionally, we aim to “Shift Right” performance to learn as much as possible from performance analysis in production, and feed that knowledge back into the development and test process. In this article I list a few ways we can do that.
- Our framework is not tied to any particular tool or technology and can be implemented with whatever tools your organisation has.
- Lastly, remember that adoption of CPE is not only about tools and technical stuff – it often takes place when an organisation is transitioning to an Agile/DevOps approach and a change of philosophy where “performance is everyone’s responsibility”, therefore it often goes hand in hand with a change of focus for the traditional performance test team towards working more with the product/feature teams, enabling and coaching others to be aware of performance.
What is CPE and why is it important?
Continuous Performance Engineering (CPE) is the practice covering all performance-related activities throughout the lifecycle of an application. This can include many activities, from performance checks at unit test level, through automated browser front-end analysis and API load tests, to analysing performance in production.
We at ALTERSIS Performance use the slogan “Shift Left, Shift Right, Automate Everything” to describe our approach for CPE:
- Shift Left – As many activities as possible should be done early and integrated into the CI pipeline, in order to detect performance issues during the build process.
- Shift Right – Wherever possible we should consider the performance of the application in production and try to use the information that we get from production to improve the development and testing process.
- Automate Everything – The manual load of performance engineering work has traditionally been very high. We aim to automate as much as possible so that the time of performance engineers can be freed up from tedious tasks to focus on adding value to their organisation.
Why is this important now?
Performance continues to become ever more critical and links are regularly proven between performance and user satisfaction, conversion rates, and company profits. (If you still need persuading, check this article).
Systems and the platforms they run on are increasingly complex and hard to analyse and tune (for example, Java-based microservices running in containers, orchestrated with Kubernetes, is now a common standard – this architecture has exponentially more tuneable parameters than its monolithic ancestor)
Despite this, the expectation has been for the performance engineer to deliver more, faster, with a higher risk, to customers who have higher expectations.
Automation is one of the few things that can save performance engineers’ stress levels!
CPE is about automating as much as possible to allow performance engineers to do more with less time; to focus on the big picture instead of small tedious tasks; and to bring more value to the team and the organisation.
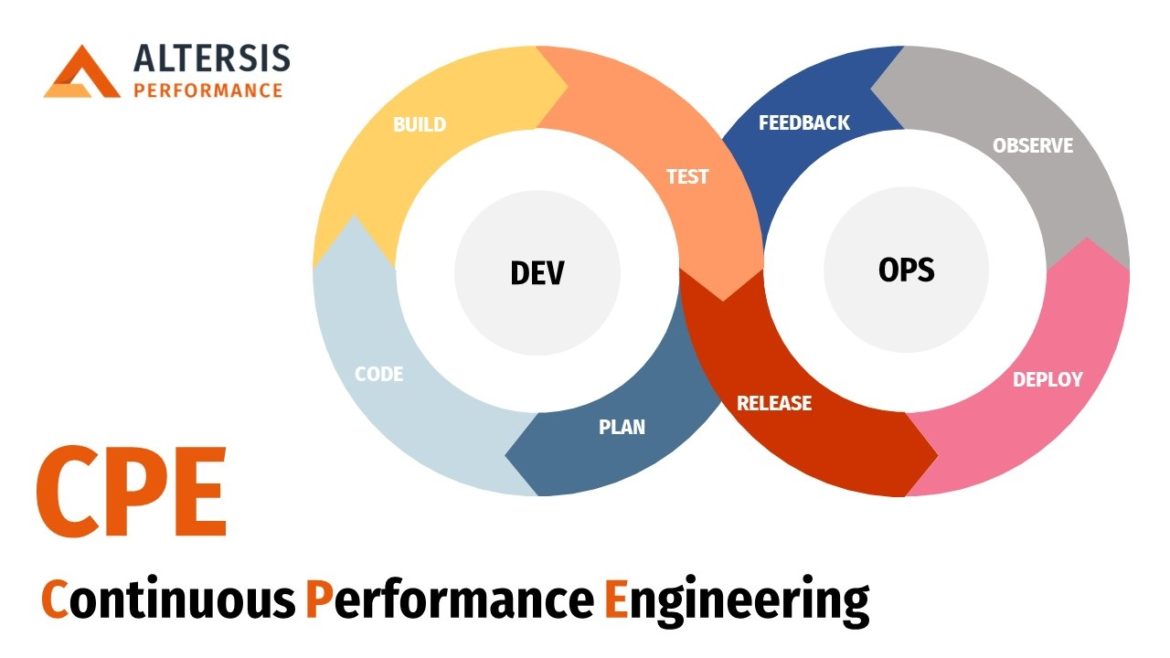
CPE Overview
The diagram below shows the different types of task that can happen at each phase of the DevOps lifecycle.
(Note that even if your organisation is rigidly adhering to old-fashioned Waterfall ways of thinking, most of these tasks are still relevant – it’s just that you will approach them in a more linear way.)
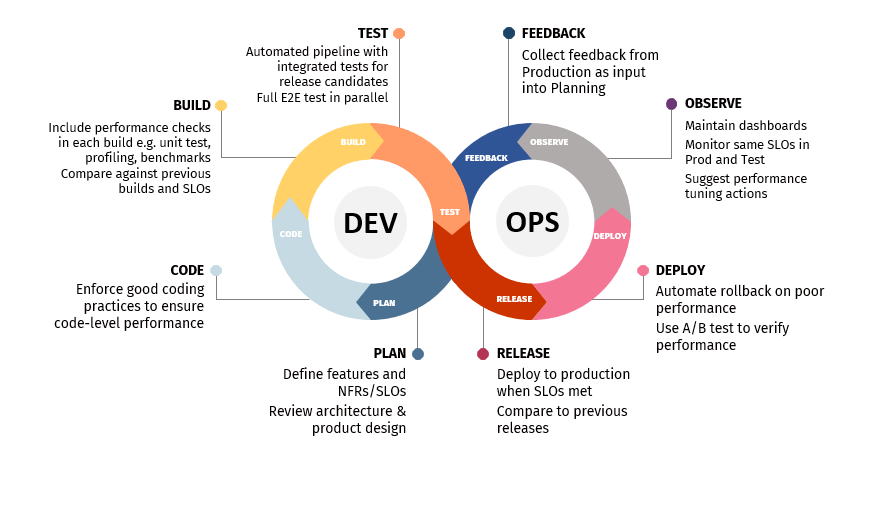
In order to keep this article short, I will not dive into each of the phases in detail – if you’re interested, I promise there will be future articles where I will do this! I will only mention a few key points here:
- Plan, Code, Build & Test are the “Shift Left” part. Build and Test are the phases where we look to automate most of our performance checks (see later for a list of the checks we incorporate)
- In terms of “Automate Everything”, of course we want to automate all the test execution and report pass or fail decisions to the pipeline. But the Plan phase now offers some more advanced areas where automation can assist. For example, the process of analysing production volumes to define the performance load model can often now be automated. Equally, many teams working on microservices are defining response time targets (SLOs) for their API calls at the code level – these can then be automatically picked up by the automated load test and used to evaluate results.
- In the “Shift Right” half of the diagram, we wish to gather performance data in Production in order to learn from the user and system behaviour and feed this back into the development process. What can we learn? Well, Production is of course the first time when our system is exposed to the real load that it was designed (and hopefully tested) for. It’s therefore our first chance to find out the answers to questions like:
-
- Our load test made a prediction of what performance would be like in Production – how accurate was that prediction, and if not perfect, why not? (Use the answer to improve the load test)
- Do the real users use the system in the way we thought they would? (Validate design decisions)
- Given how the system is being used, does this suggest any new features, fixes, or reprioritisation of the backlog? (Input into planning of next cycle)
- Is the system meeting its performance objectives, and is it helping the organisation meet its goals? (Input into the requirements of the system)
Note once again that all of these points are perfectly relevant even if you are not using DevOps or CI/CD. However, if you do have some automated pipeline process, then you are missing out on a big opportunity if you don’t include performance checks in it.
So what is our CPE Framework?
The essential elements are:
- A CI tool – it could be any tool. Internally we use GitLab and Jenkins for developing this; we have used other tools for our customers.
- A load test tool – any tool that integrates with CI tools, which most of them do – NeoLoad is one good choice for this as it has many good integration features; JMeter or any tool based on it can also be used successfully.
- A service virtualisation solution to mock any calls to other components (external or internal) so that you can deploy and run load tests without having dependencies on other applications, or affecting them with your load. We have used WireMock for this – there are many other solutions, ranging from free to enterprise-level.
- A database to store performance metrics – either a DB that you create specifically for this, or some store that already exists, such as an APM or analytics tool.
- A dashboard component – if not included in the above.
And here is what we do with these tools:
- Automate a series of performance checks – the contents of which depend on your system, but could include for example static code analysis, performance unit testing, application profiling (both front and back end), mobile device test if appropriate, API performance test, and of course different levels of load test. Any check that brings you value and can be automated is within scope.
- Send all the results to the performance metrics database and make them available to the reporting dashboard. The aim is to allow reporting on single builds, comparison of one build against another, or to look at trends over time.
- Make the same dashboards available in production as well as test so that we can easily compare between the two.
- Automate some feedback mechanisms (the questions mentioned earlier that we want to ask about performance in production).
We can go in whatever direction is most useful – for example, the diagram below shows one implementation where we used a set of Splunk queries to extract volumes from Production and automatically update the test scenario design before execution. Here, Splunk acted as the source of volumetric data, the repository for the scenario design and the performance metrics database with built-in dashboard.
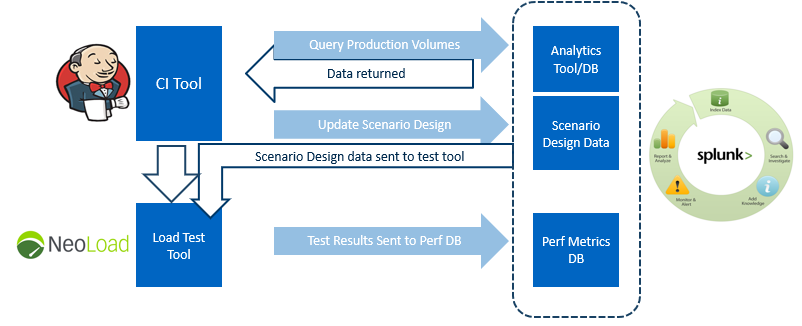
As you might expect, of course, the best approach is to start small and build up over time. Automate a small load test first, or whatever is most useful for you, and build a basic dashboard, then add features as needed. At every stage make sure that the team will get value out of the next step..
How to get your hands on this amazing framework?
At the moment, you have to call us for a demo – we will be happy to implement CPE for you, or give you guidance to do it yourself. But in fact, CPE is not a tool we are trying to sell, but rather a collection of techniques and good practices with some neat utilities and examples. At ALTERSIS Performance we have spent a lot of time developing various scripts, plugins, dashboards and so on that will save you time, but there is nothing to stop you implementing the whole thing on your own if you wish.
A CPE framework should be customised for each organisation or even each project to cover the things that are important for them, fitting in with tools and frameworks already in place. We have implemented it in various radically different ways, with all kinds of toolsets. At one customer, the CPE implementation is in GitLab, focused on running API load tests and front-end browser performance analysis – at another it is all about “Performance Test as Code”[PDF] based on Azure Pipelines and Terraform, heavily integrated with Dynatrace. The first step is to discuss what you want to achieve and what would be the most helpful outcome:
What are the performance risks that we could cover earlier?
What are the weaknesses in our performance engineering process that could be improved? And what is slowing us down right now that could be automated?
Your path to CPE adoption is… yours to decide
To what extent are performance engineers out there following these techniques already? Should you panic and feel inadequate if you are not already on this path?
I don’t think it is “panic time” yet. But I think it’s a good time to start bringing these practices in if you haven’t already.
From a non-representative survey of all the projects I am aware of, I reckon that the biggest share of organisations (say half) are not doing any automated performance tests yet; there are about 25% starting to adopt; and about 25% who are already some way down this road. This is still a relatively low adoption rate then – but this could be because I tend to work more in “conservative” areas like banking and government – perhaps in media and retail the figure would be reversed.
However, even 50% adoption means CPE is no longer at the “pioneer” stage where you have to invent solutions and customise everything by hand. If you want to start on this, all the tools you need are already there, and there are many good examples to learn from.
It takes some effort and cost to migrate to a new way of working – as with any such change. For a large organisation it may take 1-2 years to make all of these changes. How to know when it is worthwhile for you?
As stated earlier, you will get benefit if your teams are already working in some kind of Agile way; unit test and functional tests are already running automatically with each build; and you have DevOps or SRE people who can help out. The further your organisation is towards DevOps, the more it becomes essential to adopt CPE.
If you are not a match for the above, then it depends on your feeling.
Maybe you will recognise some of these warning signs that indicate your current performance test process is no longer sufficient:
- You are missing performance issues that regularly get through to production.
- Performance engineers feel like they do not have time to cover the essentials before each release (I know, some of them will tell you they have always felt like that, so let’s add that they say the problem is getting worse!).
- Your developers/product teams say they are not getting value from the performance test team; maybe some of them have started building their own automated tests.
- Your performance testers spend all their time maintaining and executing load test scripts, and rarely or never look at things like scalability, capacity or monitoring performance in production.
Interestingly, most of the points above are not really technical issues but are about the way the teams work together. Because at heart, CPE is about making performance engineering adapt to the way projects are organised, as well as adding some cool technical ideas.
Conclusion
I hope this article has given you a picture of the ALTERSIS Performance CPE vision and why we think it is so important. We believe that CPE represents the future way of working, and the signs are that more organisations are moving toward this approach.
This article is only intended as a high-level introduction, and so the detail has been deliberately kept minimal – we will show some more detailed examples in future posts.
I would love to hear your thoughts on this concept – would it be useful for you? Have you tried something similar already? Let us know




0 Comments