‘By Alan Gordon’
How well can you remember the world 20 years ago? For some of us it feels like not too long – for others, it’s before their adult lives even began.
Daily life was quite different then, without many of the things that we take for granted today. This was years before the invention of smartphones – the top-selling mobile phone was the Nokia 6610 (display 128×128 pixels, but boy, that battery life…). Meanwhile, the hottest must-have gadget was the 2nd generation iPod mp3 player with its 20GB disk space. The major theme in tech was the continuing development of the internet – 2002 was not long after the dot-com boom and bust when we were still in “Internet 1.0”, long before Facebook and its like came along.
In geology and global politics, things move slowly, but 20 years is an eternity in the world of IT – including in the software performance field. Here at ALTERSIS Performance Switzerland, we’re looking back over the 20 years that our company has been around. Come with us as we take a look back to see how the world of software performance engineering has changed – after all, knowing about our history helps us to understand the present day and prepare for the future!
Looking back over two decades, the biggest theme that emerges is the increasing pace of change, especially in people’s everyday use of technology. In only 20 years we have moved from a time when the internet could still be dismissed as a temporary fad, to today when most people have an always-on internet connection in their pocket and there are billions of connected devices from cars to washing machines. Many companies focus on their web applications as a first priority, above real-world stores, offices or paper publications, and this has changed the everyday perception of software performance to being critical for doing business, and even for commercial survival.
Technology change
Focusing on performance engineering work, one of the biggest changes in the last two decades is in the type of application that the average performance engineer has to work on. Going back to the 1990s, performance was relatively simple, often based on the throughput/efficiency of a single tier such as a mainframe or database, or perhaps modelling network characteristics. As we got closer to the turn of the millennium, three-tier architecture systems based on Java became increasingly common. Applications started to be made available over the internet, being accessed from browsers, and the need for load testing increased because critical applications could become very heavily loaded. Applications still tended to be monolithic in design, with all components closely connected. Middleware systems like CORBA or remote procedure call protocols like DCOM allowed applications to be integrated. These were the systems that we commonly found ourselves testing 20 years ago.
In the 2000s, a shift towards service-oriented architectures began, where applications instead of being monolithic, were divided into a collection of services that can be used independently. This trend has continued until today when it is the most common way to build large applications, even in cases where it is not necessarily the most efficient.
In parallel, other changes were transforming the IT world. The software development process was being rethought with the rise of Agile techniques. Software started to be developed incrementally over many “sprints” rather than in one “big bang” approach. This resulted in challenges for performance engineers – used to running tests against an almost-finished product close to go-live, we now had to consider how to draw useful conclusions much earlier. There was increased pressure to deliver results quickly – and this also forced a rethink about how to approach performance engineering (see later).
Another major change was the increasing ability to deploy applications flexibly using virtual machines, at first on local hardware, but later on cloud platforms and in a more automated way. This had positives in improving our test environments, but also led some to the wrong conclusion that performance engineering was no longer necessary because so much more compute power was available when needed. Thankfully this trend is fading as most people are now aware that performance issues are often the result of poor code or configuration, and that simply adding more compute power will lead to high costs.
The above changes were made easier by the gradual rise of open-source software. In the field of operating systems, the change from high-end workstations (Sun, SGI, HP, etc) running proprietary UNIX (Solaris, IRIX, HP-UX) to commodity AMD64 kit running Linux. In 2001, Microsoft CEO Steve Ballmer famously said, “Linux is a cancer that attaches itself in an intellectual property sense to everything it touches.” Now, Microsoft has built Linux into Windows (WSL) and supports FreeBSD on Azure.
In summary – from a modern-day perspective we can see that there is a shift over time towards systems becoming more distributed, powered by the greater availability of virtual machines, cloud platforms, faster networks and the growth of the internet. This has led to much more powerful systems but also has vastly increased the complexity of large applications.
The founders of ALTERSIS Performance saw earlier than most that ensuring the performance of complex software applications required an engineering approach, to make sure it was built in according to well-defined principles. It was a key principle of the Altersis APEP methodology that this process started while developing the application, and performance was not just a feature that could be added later as an afterthought.
Performance Engineering tools
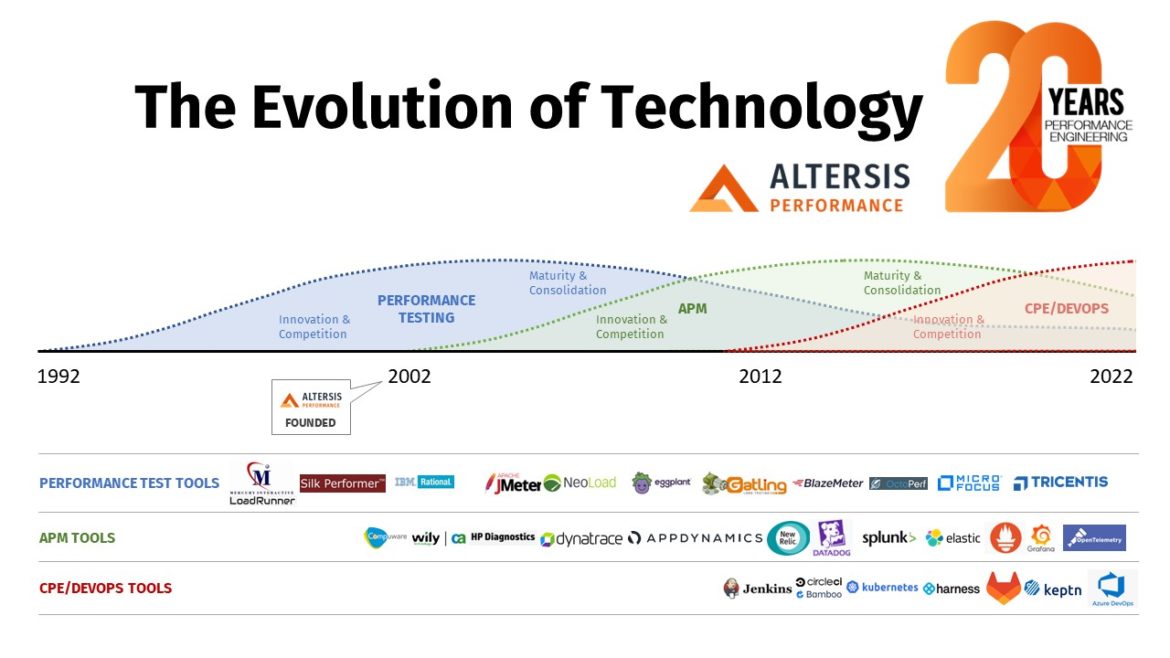
The diagram below shows the broad trends in performance engineering tools and approach over the last few decades. Of course, it’s a simplification, but we see three major trends over this time, starting with the rise of performance testing in the 1990s, followed by Application Performance Monitoring a decade later. More recent years have seen more innovation in the area that we in ALTERSIS call Continuous Performance Engineering (applying performance engineering techniques to CI/CD and DevOps) and other “next generation” technologies such as Kubernetes and the use of AI/Machine Learning tools.
The field of performance engineering tools was much narrower in the early 2000s and focused around load testing. LoadRunner was the dominant player with various other tools competing for market share, all rather similar in design. The high price of load test tools at that time might surprise people today! Open-source load test tools were not viable for anything other than the most basic tasks – even when early versions of JMeter appeared in the second half of the 2000s, it was limited and difficult to use compared to today’s version.
The 2000s were the decade of the load test tool, but even by the early 2010s growth and innovation had slowed. The last big innovation was arguably the introduction of the TruClient browser-driven protocol into LoadRunner, more than a decade ago. Since then, improvements have focused more on integration with APM tools and into the CI/CD process. By the last few years, the rate at which load test tool vendors are being acquired or simply exiting the business speaks for itself. Load testing has become a commodity which will be increasingly automated and is no longer the domain of deeply expert specialists – and this is for the good of all!
How about monitoring tools? The APM tool as it is known today did not exist at the turn of the millennium – although there were more or less effective ways to monitor each individual component, it often had to be done by manually setting up scripts to collect and process metrics.
By the mid-2000s several useful tools had appeared, initially focusing on specific technologies. (This writer’s first experience being with Compuware Vantage and Wily Introscope, although I am not trying to make a definitive statement on what was “the first” APM tool!) In the 2010s, major players like AppDynamics and Dynatrace competed to cover more technologies and extend coverage from low-level technical monitoring to business-focused dashboards.
At that time, there was a differentiation between tools that focused mainly on log analysis, like Splunk, compared to monitoring-focused tools; but this has changed in this decade as vendors converge on coverage of metrics, traces, and logs as the three pillars of Observability.
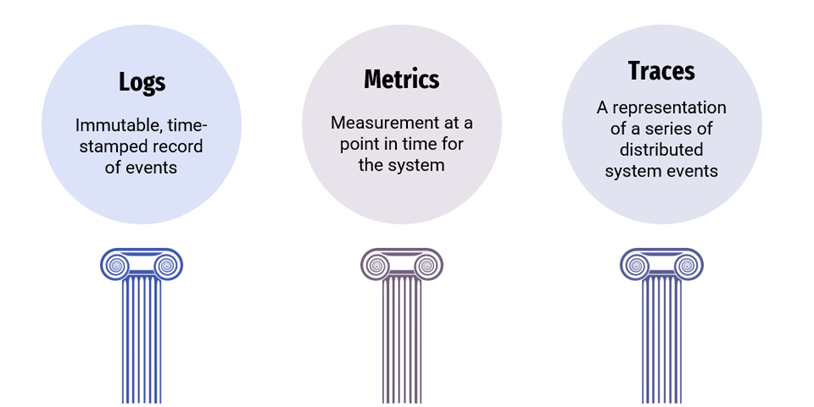
Today, software performance has increasingly become the responsibility of the whole team. The “APM tool” has evolved from something that primarily helped performance engineers and the Ops team to do their job, to being the key information provider to all stakeholders, from business to developers.
We see that the “APM” term is reaching the limit of its usefulness and in the future, it may be more useful to refer to APO – Application Performance Observability – reflecting the fact that Observability is much wider than only software performance-related. The future challenge for the “APO” engineer lies in ensuring the performance of any application is measurable from Dev to Prod, and using this to provide insights that product and feature teams can use to make a difference to the organisation.
Rather like load test tools, this may in the future increasingly be done using open-source software. Product suites like Elastic now offer a wide range of features that teams can customise as needed, with key technologies like Prometheus becoming standard.
The Performance Engineer role
As we have seen, tools and technologies have radically changed, but how about the way that we performance engineers do our job?
Today, we are well aware that performance engineering is much less about testing and rather more about doing whatever is necessary to improve the application performance – but twenty years ago it was largely about “testing” and teams tended to work separately in silos. Performance was usually seen as part of Quality Assurance, who would receive the latest release and either accept it or reject it, but was definitely not part of the team who would actually create the release. Although many people I worked with were deeply skilled and able to analyse applications and suggest tuning improvements, that was seen as going beyond the basic job. (And don’t forget that the tools to provide a comprehensive view of metrics, traces, and logs did not exist at this time.)
It was often a big effort to convince everyone of the value of doing performance testing – even when it was mandated, it often became a “tick in the box” exercise before go-live which gave limited value. Although there was never any specific point when it felt like we had won this battle, the importance of software performance increased steadily, like a tide coming in. Now, most in IT are well-educated about the importance (perhaps because those who are not went out of business…?)
Performance testers were often a separate team (or more often, an individual) who sat in their corner and “worked their magic” and were best left alone. I always felt that this was counter-productive and projects who worked in this way ended up with worse performance than ones where we could collaborate with the rest of the team and involve them as much as possible.
Happily, today I often see entire teams, from business analysts to developers and architects, deeply involved and passionately discussing performance requirements and designs in a very knowledgeable way. (Of course, I know this is not universal and in many places, this view still has not penetrated – but it feels like great progress to me nonetheless). We have been able to do this because of an increased focus on “shifting left” performance activities to integrate early testing into the pipeline. Performance engineering has changed from something that happens outside the core team, to a key activity that the whole team can take part in. To me, this is the biggest change, more important than any new tool development, and our role will continue to evolve. Performance engineers must increasingly evolve to become performance coaches, helping to educate their team and providing frameworks to enable others – far from the day when we did it all ourselves.
Performance engineering for the next 20 years?
Here are some of the most important topics today in performance engineering that we think will dominate this decade and beyond:
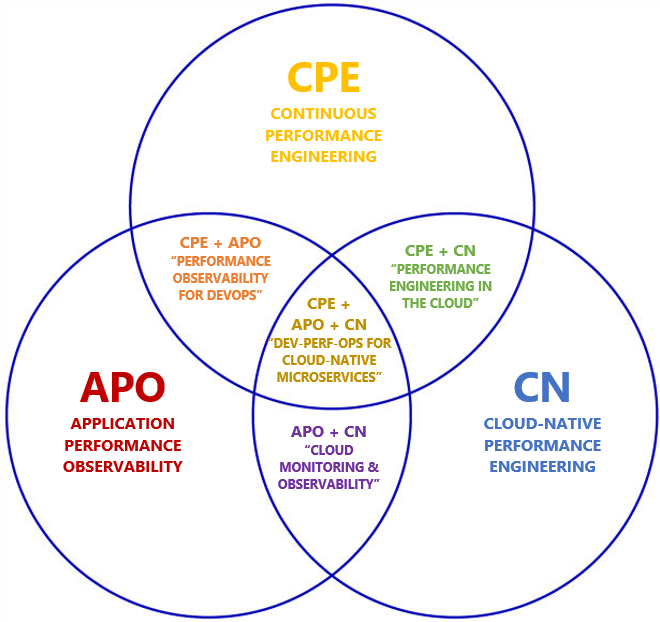
- Continuous Performance Engineering – in ALTERSIS Performance, this is our term for how we apply performance engineering to a CI/CD or DevOps process. It is not only load testing integrated into the pipeline, but covering as many performance risks as possible in the build process, and also looking at application performance in production to learn as many lessons as possible. Our motto for CPE? “Shift Left, Shift Right, and Automate Everything!”
- Application Performance Observability – as explained earlier, this covers the performance aspects of Observability and will be the future direction of today’s APM.
- Cloud-Native Performance Engineering – almost everyone is either running on a cloud platform, migrating to cloud, or planning the migration. The performance engineer must already consider new layers that didn’t exist previously, like Kubernetes orchestration, adding to the complexity of system configuration.
These topics do not exist in isolation but there are many areas of overlap, so we can think about the diagram below – where does your organisation sit?
Looking further forward, it seems likely that ever-increasing automation and use of Machine Learning/AI tools will continue to be applied to the above areas – AI tools becoming more necessary as system complexity increases past the point that human engineers can handle. Kubernetes configuration and cloud cost optimisation are two of the areas where this is already beginning. But it can go much further! As the volume of performance metric data increases, AI will transform the way we understand and gain insights on everything from end user monitoring to performance test analysis. Equally, developer assistance tools like GitHub Copilot will develop and may become a standard tools for developers. This should ensure better performance and resilience at code level. This would mean many fewer issues related to code defects, and more time to focus on configuration and scalability – just where it is needed in the future of even more widely distributed cloud-based systems.
Summary
It has been exciting to be around to see the journey of software performance engineering from being an optional activity to the central place that it occupies today. Changes in user perception, application platforms, the way that projects work, and many other factors combined have led to rapid change in what our role is and how we go about it.
Happily, I feel that we are in a much better place today. And the pace of change is still high. In this decade, it’s likely that new factors such as increased automation and use of Machine Learning/AI tools will take performance engineering to new levels. Twenty years from now, I’m confident there will be new insights and greater changes to look back on.




0 Comments